人人都是唐宋八大家
借用我司“人人都是徐志摩”的微信小程序名称😂。
楔子
它从哪里来?它要到哪里去?
Q:为什么又要做一个古诗生成的东西呢?
A:因为古诗生成这个简单啊!
Q:那你这个跟别人的古诗生成有什么不同吗?
A:嗯…稍微有些区别吧,大部分的写诗还是给定几个字词来生成的,我们这个是给定一句话来改成古诗的。
Q:就这?那有什么ruan用?你这也没什么技术难度吧,不就是S2S跑一下嘛。
A:额…那我问问你,鲁迅的名言“其实地上本没有路,走的人多了,也便成了路。”这句话能用古诗写出来吗?
Q:额…一下子想不出来。问题是你以为大家都能写出这么有哲理的话吗?
A:不需要呀,只要拍个照片,我们也能帮你写成诗啊。
Q:哇,太厉害了,赶紧介绍一下吧(此处为作者YY😂)
介绍
举几个栗子
先给大家看几个例子感受一下,给定一段现代文,生成相应的古诗词:



附赠两张马老师经典语录:


只给定图片,生成相应的古诗词:



一个完整的例子
这里介绍一下整个产品的使用方法。
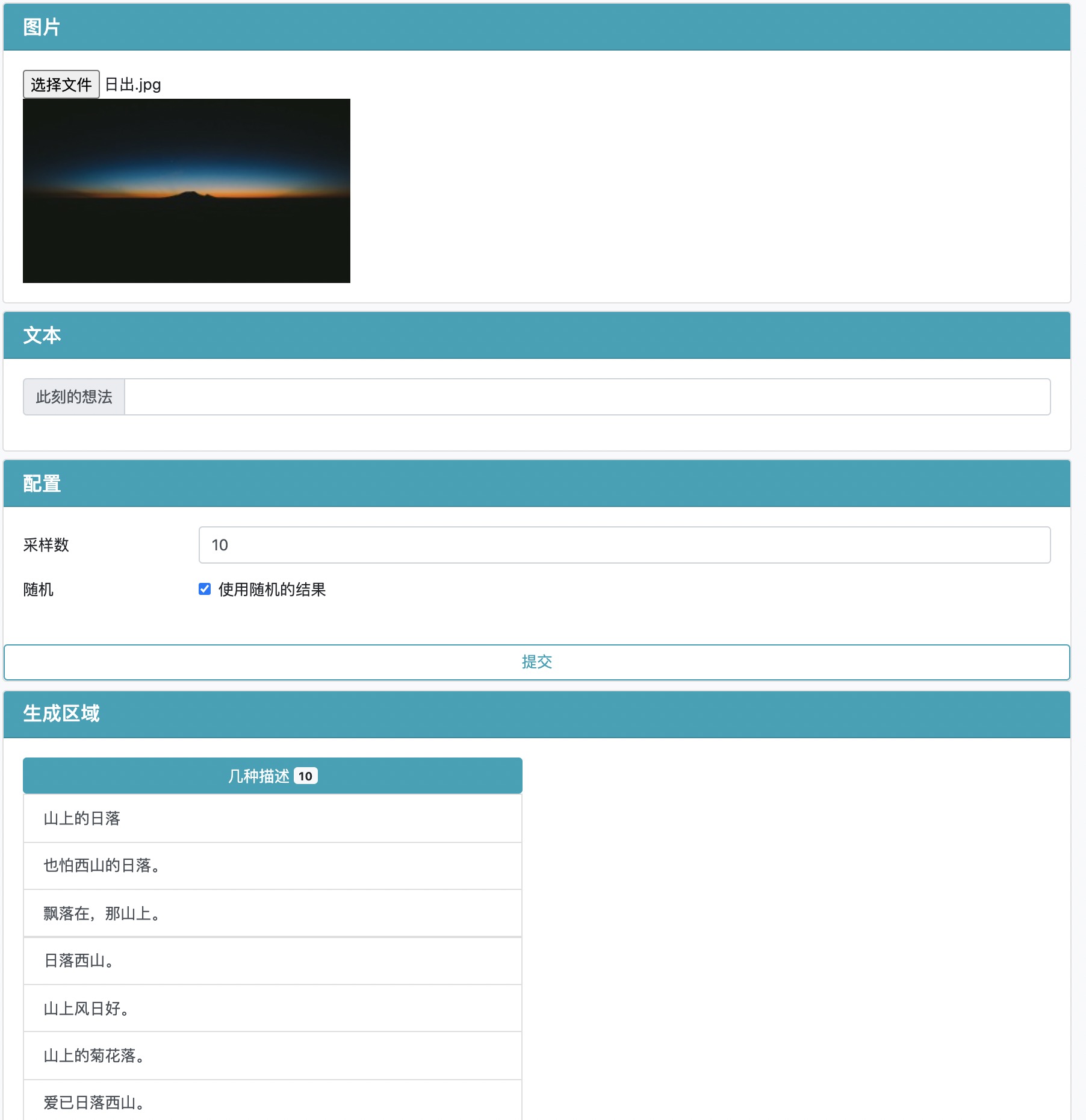
先挑选一张自己喜欢的图片,比如这张日出的照片

上传后,可以不在文本区域进行输入,直接点击提交,我们会对图片进行识别,并且返回相关的一些描述:
如果在文本区域输入了文本,那么我们就会直接用你输入的文字再加上一些相关的描述作为返回结果。
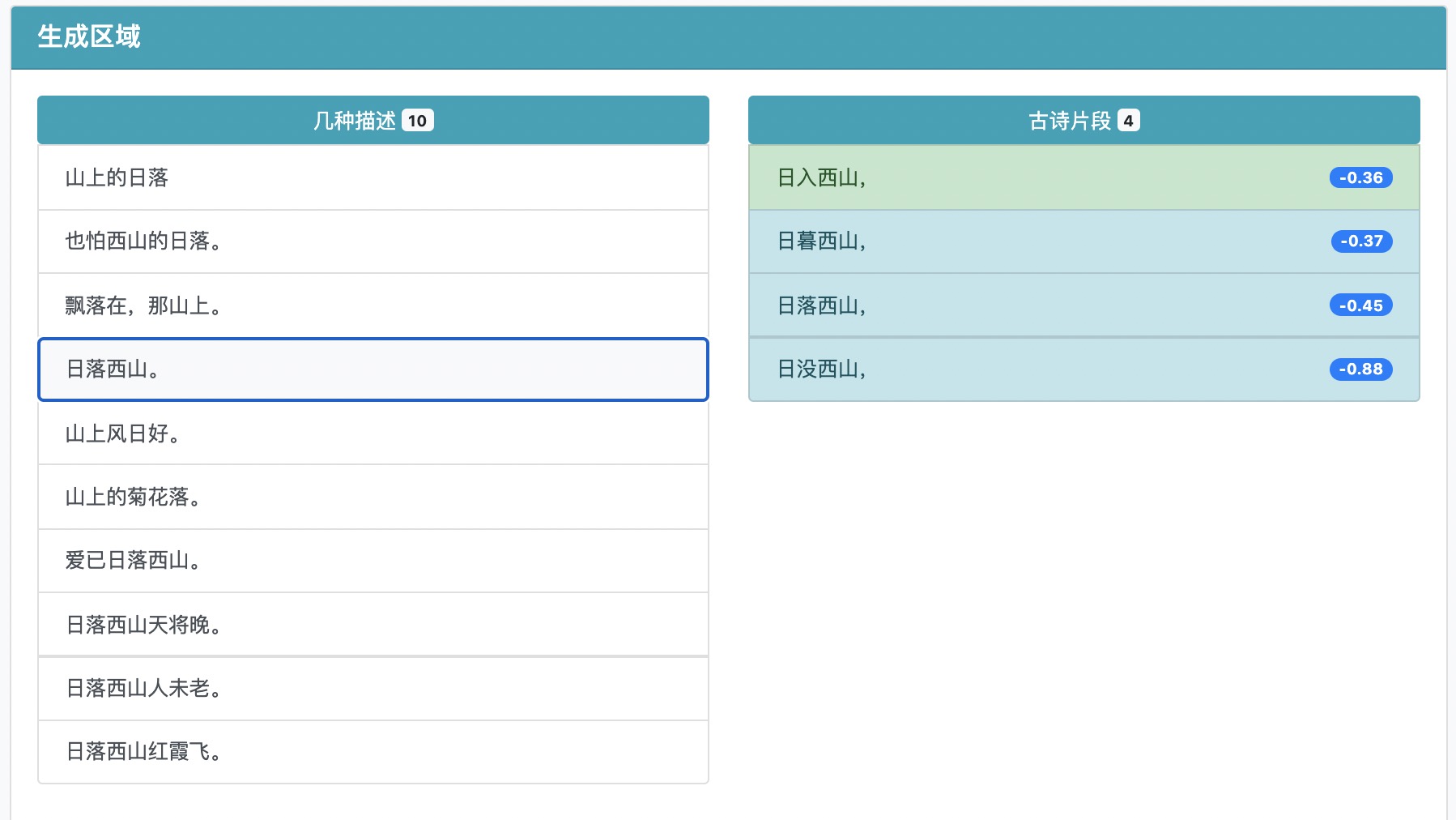
选择一个带有一些意境的描述(这样的描述生成的效果会更好一些),就可以生成相应的古诗【每次点击都可能会生成不同的结果】:
当然,如果都不好的话你可以直接在文本区域输入文本,我们会默认第一个返回你的输入文字,这样你就可以根据自己的输入来生成古诗了。
在古诗片段中选择一个你觉得还合适的,然后就会生成下一个片段:
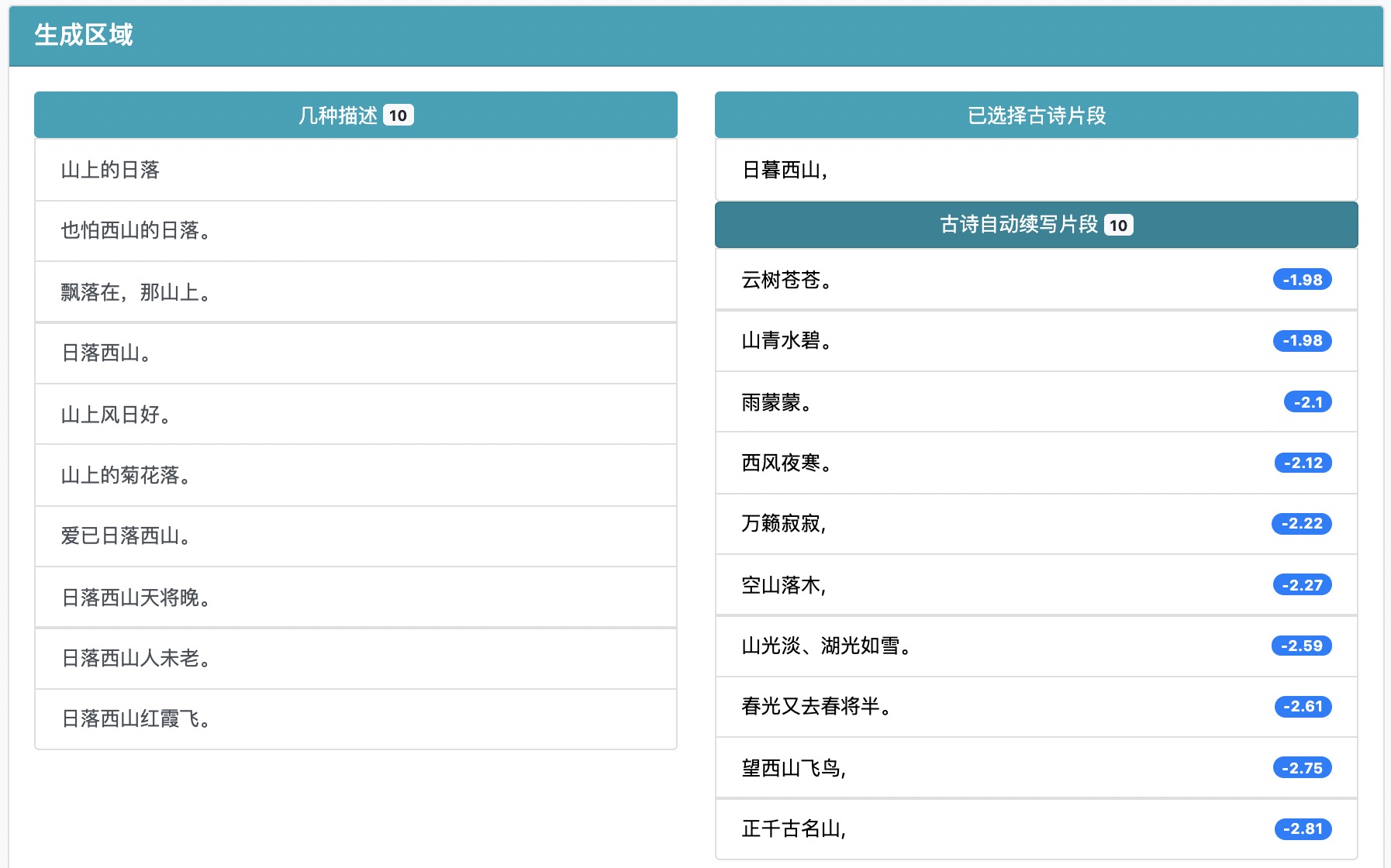
你可以不断的通过点击、选择的交互得到你想要的结果。当然,如果你觉得生成的句子或者选择的某句不好,可以点击已选择的古诗片段,我们会重新生成结果。
你可以通过点击”完成“按钮或者选择了生成结果中带有“【完】”的,来结束你的创作(不一定要生成完整的古诗词,即使是几句也是挺有意思的)。
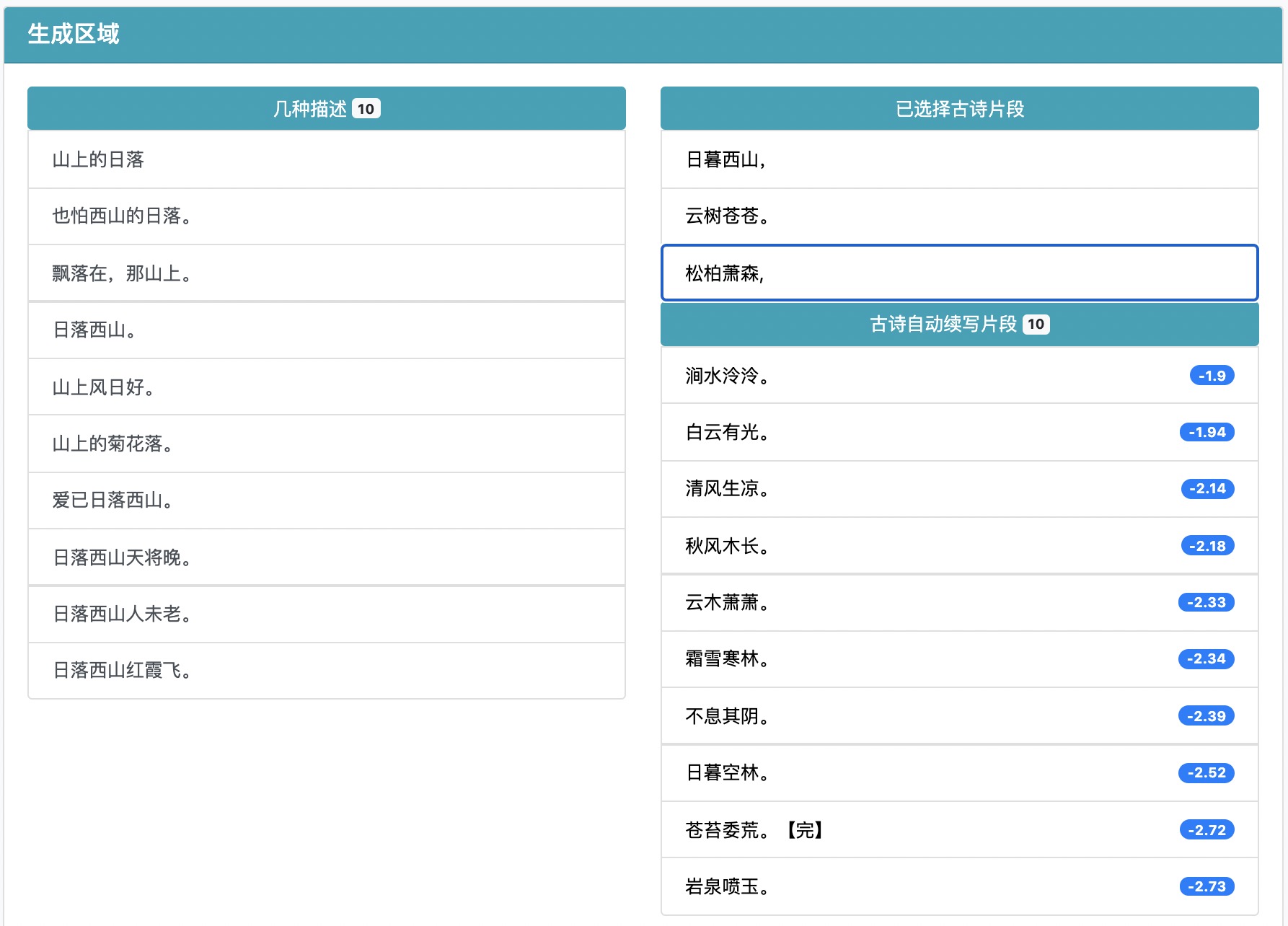
最终,署上你的大名(当然你也可以选择匿名),点击分享,就可以让大家在浏览界面欣赏到你的大作了!
插播一条广告
当然,如果有合适的合作机会也欢迎与本人(xueyou.luo@aidigger.com)联系,毕竟这些服务都用着公司的资源😂。比如卖茶叶、卖白酒,需要一些古典文学来点缀一下产品的,朋友圈需要发点文艺气息的,欢迎联系。
另,我司(艾耕科技)在内容理解、内容生成、内容营销上有着丰富的经验和竞争力十足的产品,由于业务发展太快,急缺前端、后端、NLP和CV的同学,有兴趣的同学欢迎联系我。
项目地址
算法细节
这里介绍一下整个项目的一些算法和流程,有兴趣的同学可以看看。
数据准备
我们用到的是S2S模型,那么最大的问题是从哪里获得这么多平行语料呢?
最简单的想法当然是利用古诗的现代文翻译数据了,于是GitHub上搜了一下,忘了是哪个地方了找到了开源的部分平行数据【可能是清华的九歌团队,但是我后面去确认的时候发现找不到这个数据集了】,但是数据量非常少,训练集只有3362条😂,放弃这个数据。
发现有个古诗文网里面有很多诗文,并且有译文。于是又在GitHub上搜到了有人已经爬过这个网站了,感谢这个项目,我们直接拿这个数据,并做了一些后处理,将古文和现代文对齐了一下,大概有2万多条平行语料(句子级别的)。但是感觉还是不够,只能拿来做个finetune的数据,我们再找一些更大的预训练语料。
在我写这个博客整理资料的时候,发现这位小哥在大概一年前做过类似的项目😄,不过他是生成整首诗。
我们又在GitHub上找到了比较全的古诗词的数据,可能是这个(😓几个月前整理的数据了,所以原谅我不记得是否是真实的出处了,后面会把我用到的训练数据开源的)。然后利用百度的文言文翻译将它们翻译成现代文,这个数据集就比较大了,大概400万对句子级别的平行语料。
这里可能有同学会问为什么要句子级别,而不是诗词级别的语料?主要是考虑到大部分情况下,让用户写一句描述还是比较简单的,但是让用户写个能翻译成整首诗的段落还是难度比较大的,可能就劝退了很多人,因此我们就选择了句子级别的语料。
此外,我们还找到了歌词、现代诗、散文的数据集(感谢万能的GitHub),这些也是我们的语料。
模型训练
现在这年代你不搞个预训练的模型都不好意思说你是做NLP的,因此,我拿了公司姜夏同学原来预训练的小型T5模型,由于它是在新闻、维基等语料上训练的,因此我在它的基础上继续预训练。
预训练方法与T5一致,语料用到了上面提到的古诗、歌词、散文等,得到了一个(可)能理解古文和现代文的T5模型。
当然,我觉得这个预训练不是必须的,因为百度翻译后的数据就已经上百万了,对于S2S模型来说够了。
也另外单独训练过一个字级别的不加预训练的S2S模型,但是效果差很多,而且普通结果偏短。可能是我这边没有仔细调参。
之后我就在百度的语料上继续训练模型,得到了一个baseline的现代文转古诗词的模型。
同时我也用古诗词数据训练了一个Denoise Autoncoder模型,主要是想对模型的结果进行一下优化,但是发现这个DAE没什么用,对结果基本不做改变,遂放弃。
也试过把散文数据翻译成文言文加到原来的百度语料上进行训练,但是效果变差了,遂放弃。
最后就是在整理的比较不错的平行语料上finetune刚刚的baseline模型了,得到了“最终”的古诗词转换模型。加个beam search,已经可以生成还不错的古诗了。试着用鲁迅、毛主席、张爱玲的名言去生成,能得到还可以的结果。
但是,我们就止步于此吗?NONONO,我们才刚刚开始。
进一步改进
使用beam search的话我们只能得到一个结果,虽然这个结果还不错,但是不满足我们想要交互的功能,因此需要更加多样性的结果。最简单的方法就是做采样了。参考谷歌的《Towards a Human-like Open-Domain Chatbot》,我们使用top-k采样,采样20个结果后再进行排序,排序的score也比较简单,就是每条结果的对数概率除以它的长度。
top-p采样需要设置一个比较合适的p值,否则生成的结果就比较难看了。
看上去结果还不错,但是还是存在一些生成的质量不高的问题。我需要有个质量打分模型,因此我把歌词的数据过了模型,得到结果后人工标注了大概1000条左右的质量评测数据(只标注结果好中差三类)。在这基础上,用bert和t5都跑了个评分的分类模型,总体效果都不是特别好,f1大概0.7左右。先凑合着用这两个模型分别对其他生成的歌词结果进行打分,筛选出来一批结果,然后把这些结果和原来找到的平行语料合并再训练了两个生成模型,这两个模型用来做采样。因此,大家看到的古诗的生成其实是三个模型的结果,一个是平行语料训练的模型的beam search结果,另外就是这两个模型的采样结果,再总体rank后的效果。
更好玩一些
考虑到可能很多人有写作恐惧症,根本就不知道要写点什么内容来进行生成,因此我们再进一步,考虑用图片进行输入,毕竟拍个照片还是简单的。最直接的想法是搞个image caption的模型,本想找个开放的接口,但是搜了一圈国内大公司的平台,都没有。中文的话其实AI challenge有放出过训练集,但是我不想自己训练了。那段时间看到微软说它的image caption达到了SOTA水准,而且还超越了人类,刚好我司有微软的Azure账号,因此就用公司的账号开通了这项服务,测试效果还可以。问题是返回的结果是英文的,因此只能再加个翻译服务,把它翻译成中文😂。
但是,image caption出来的结果其实都是对图片的简单描述,虽然可以做到比较准确,但是写诗最重要的还是意境,比如要多一些的形容词。为了扩展意境,我们把歌词的数据放进了ES,通过搜索匹配的方法,把image caption的结果进行扩展。这样就得到了我们最终的描述结果。
有了描述、有了生成,还差一步就是怎么把单句的古诗词进行续写,让它变成更完整的内容。简单的想法当然就是用古诗的数据finetune一个中文的gpt2模型了,而且现在GitHub上也有很多人开源了模型。但我这里没有选择gpt2,因为gpt2的时间复杂度太高了,而且我希望是用户可以交互式的完成整首诗词,如果部署在cpu上这个时间不太能接受,加上也不想占用公司gpu资源,因此就训练了s2s的补全模型。基本上就是把t5的模型在诗词上进行finetune,输入是上文,输出是下一个短句。
好了,到这里整个算法部分就结束了,前端由于我只会简单的,因此就用了bootstrap+jquery实现,大家可以包容一下😂。
再来一条广告
推广一下本人的公众号😆,大家关注一下公众号“考拉和羊”,不定期分享各种文章😂。
