AiSK - OpenQA的简单实践
最近公司业务需要,研究了一下OpenQA相关的工作,我把模型整理了一下,部署了一个demo,有兴趣的同学可以尝试一下。
先放几个效果【答案内容来源网络,仅供参考】




以上就是主要内容了,如果对算法感兴趣的同学可以继续看看。
开放问答
开放问答是指基于涵盖广泛主题的文档集合给出问题的答案,比较常见的就是搜索引擎里面一些小卡片的结果,以及一些APP里面的搜索结果,都是开放问答。
开放问答也有几个分类:
- 基于知识图谱的KBQA,比如你在google搜索下面的查询:
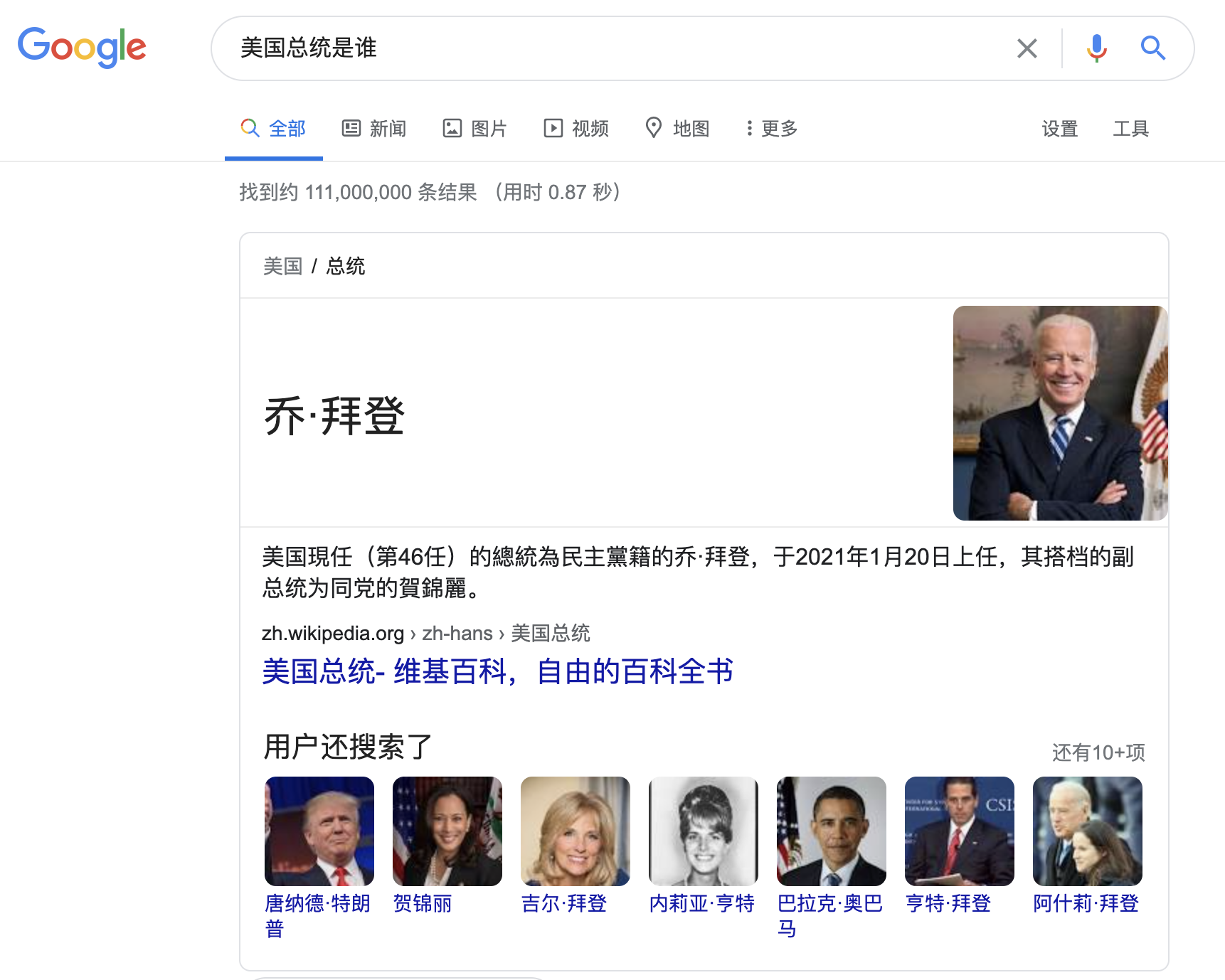
- 基于非结构化文本的问答,比如你搜索下面这个query,我们demo里面的也是这类。同时我们也只考虑能够从文本中抽取出答案,而不是要生成答案。
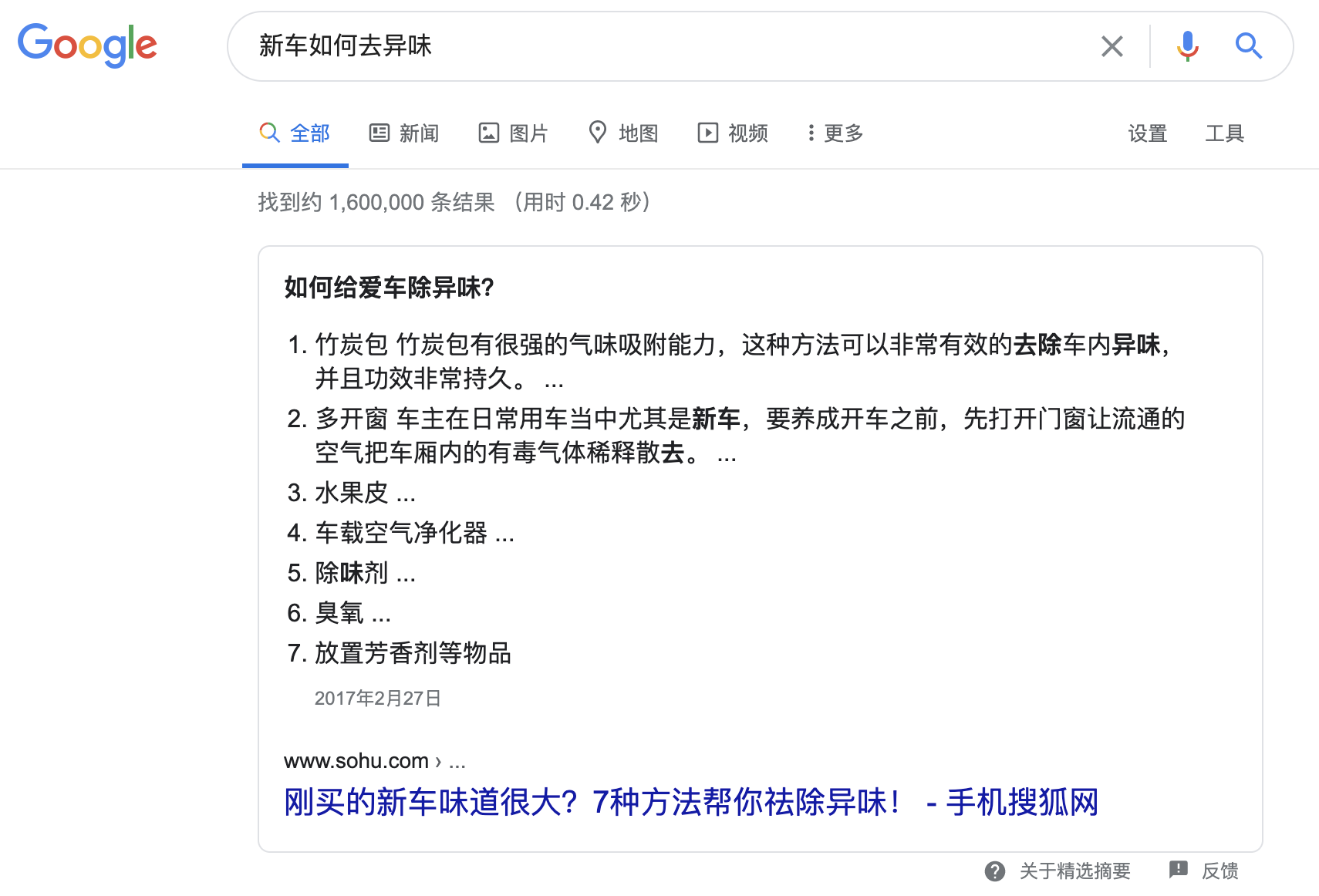
- 社区问答(Community Question Answering),现在是UGC的时代,在论坛或者APP里面用户本身就产生了很多问答对,如何从这些噪声大的数据中提供优质问答服务也是有意思的研究领域。
- 还有比如基于半结构化数据的QA,比如从表格里面提取答案,这块我没有涉猎所以不清楚。
数据!
要做算法最关键的还是数据问题,中文比较好的资源就是百度开放的DUReader数据集,有300K的问题+1.4M的文档,数据分成两类:一类是来自百度的网页搜索;一类是来自百度知道。我们在做的时候主要用到时网页搜索的数据集。
DuReader目前还有排行榜,有兴趣的同学可以试试,目前最高的是美团的团队,Rouge-L和Bleu都超过60多了,感觉很高了😂(为啥不是用EM和F1这样的指标呢?)。
Baidu Road: Research Open-Access Dataset
算法
OpenQA比较常见的解法是将问题分成两个阶段:Retriever + Reader。Retriever负责从海量文档中获取与问题最相关的(最可能含有答案的)文档,Reader则是从这些文档中提取最佳的回答。
DrQA自称是第一个基于神经网络的开放问答系统,它使用了维基百科的数据作为它的候选集,通过tf-idf这类词袋模型的方法召回文档,然后再训练了MRC的模型(当然,那时候还不是BERT,现在BERT是标配)预测答案。我们基本也是这个套路,只不过召回直接使用了百度的搜索,然后通过BERT训练了MRC模型,分别抽取召回文档的答案,再对答案排个序就输出了。
改进
可以发现如果我们分别对每个文档抽取答案,答案之间的分数是没法直接比较的,而且也没有考虑到召回文档的相关性和重要程度。所以比较简单直接的想法就是直接多文档联合抽取:Multi-passage BERT。
这个模型提到了两个点:
- Shared Normalization:每篇文章仍然单独抽取答案,但是算Span的概率的时候会把所有文档一起考虑进来,这样不同文档之间的Span的概率就变得可比了。
- Passage Re-Ranker:预测文档的相关程度,最终这个Ranker的分数也可以用在预测Span上,用来提高高相关文档的Span概率。
我网上找到的美团分享,他们用的大概就是这个技术【分享很不错,对问答感兴趣的同学可以仔细看看】:
当然我们也可以训练一个answer ranker,比如某个答案有更多的evidences,或者某个答案的evidences能够覆盖问题的大部分信息,那么它们都更有可能是正确答案。
同时我们也可以看到,现在很多Sparse attention的BERT能够处理非常长的文本,它们在一些OpenQA的数据集上表现也不错,这也是个可以去探索的方向。
E2E
前面的方法其实Retriever是没有得到训练的,现在也有人研究使用Dense retriever,E2E的训练整个模型,比较有代表性的包括:
- ORQA
- REALM
- DPR
DPR的思路比较简单,可以通过Q-A对来训练一个question和doc的相似度模型,训练好之后就可以对所有的doc进行encoding,然后用类似FAISS的框架做成index,方便inference的时候进行检索。Reader这块他们其实还是用了前面提到的Multi-passage BERT。总之效果还可以吧。不过我个人还是比较喜欢pipeline的方法,主要是各个阶段的结果还是比较可控的,可以通过多加些特征或者模型来提高最终的效果。
一个小问题
另外,我们发现对于一些步骤类的问题,单纯的基于抽取是比较难获得比较好的答案的。个人感觉可以有如下两种尝试:
- 可以用T5训练个生成类型的QA模型,直接将步骤比较精炼的生成出来;
- 如何同时抽取多个片段的信息【只把主要的步骤内容抽取出来】。
参考文档
大部分参考资料其实来自于ACL2020的OpenQA的tutorial,非常不错,感兴趣的可以听听看看。
另外也可以在paperswithcode上面看看数据和SOTA的论文。