Xueyou Luo @ Eigen Tech
随着Bert,GPT-2,XLNet的推出,效果提升的同时一个很大的问题就是这些模型都太大了,我们不像google有那么多tpu资源,如果想要自己训练这些模型就得想想其他的方法。这里我们研究了几种在有限硬件条件下加速模型训练以及如何训练大模型的方法,供大家做参考。虽然我们探讨的是如何训练大模型的方法,但是对于训练普通模型仍然有意义。
这些方法主要包括以下几种,我们分别进行介绍:
- 混合精度训练
- XLA加速
- 分布式训练
- 梯度累积
混合精度训练
原理
我们训练模型一般都是用单精度(FP32)的参数,但是其实我们还使用半精度(FP16)。半精度可以降低内存消耗,从而训练更大的模型或者使用更大的batch size;同时运算时间受内存和算术带宽的限制,在有些gpu(Tensor cores)上可以为半精度提供更大的算术带宽,从而提高训练效率,减少inference用时。
但是简单的将模型变成FP16并不能work,FP16只能表示[$2^{-24}$, 65,504],相比FP32的[$2^{-149}$, ~$3.4×10^{38}$] 数值范围大大受限。因此需要额外的一些trick来保证模型能够收敛到跟FP32一样的结果。主要包括以下三个方面:
-
FP32 Master copy of weights
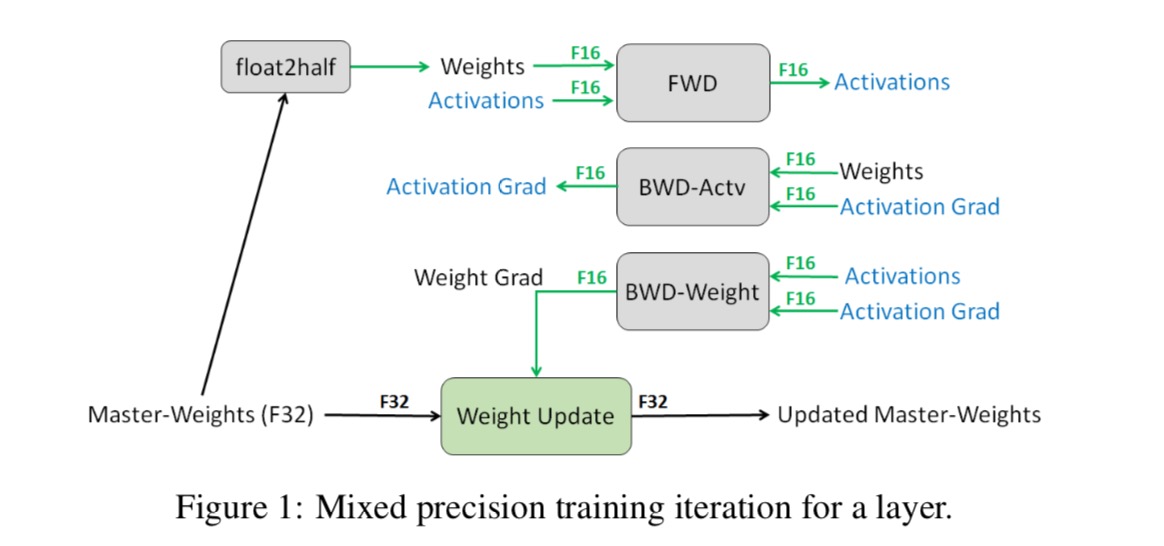
训练时,权重、激活值和梯度都使用FP16进行计算,但是会额外保存FP32的权重值,在进行梯度更新时对FP32的权重进行更新。在下一步训练时将FP32的权重值转换为FP16再进行FWD和BWD的计算。这里是因为使用FP16进行梯度更新的话,有一些梯度过小就会变成0,从而没有更新。还有就是权重值比梯度值大太多的时候,相减也会导致梯度消失。
可以参考下图了解整个训练过程。这也就是为什么叫混合精度训练的原因,我们并不是只用一种精度来进行训练。
-
Loss Scaling
一般我们在训练模型的时候,梯度的量级都非常小,由于使用了FP16,就会导致一些小的梯度直接变成了0,下面这张图展示了激活函数的梯度值的分布情况。可以看到除了64%为0的梯度值,其他非0梯度中有一大半都不在FP16的表示范围内。
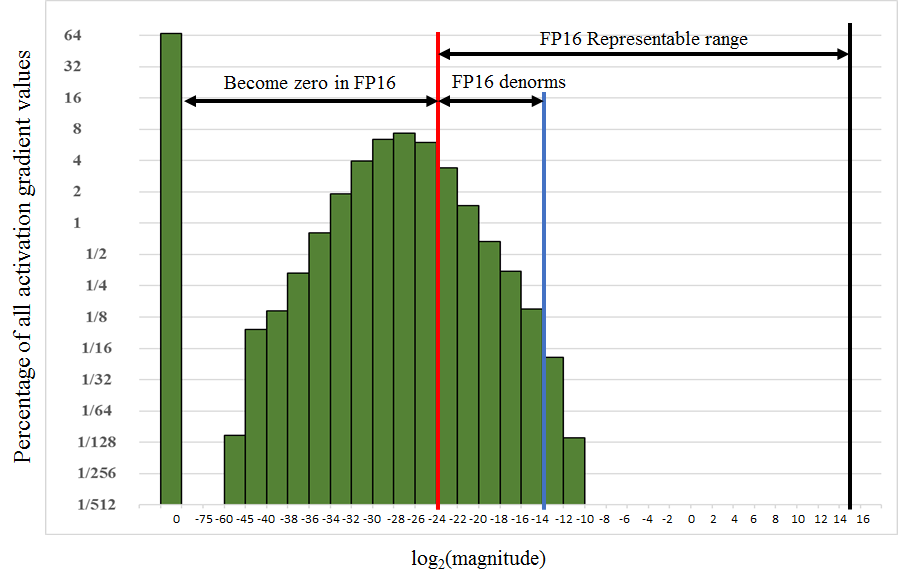
我们注意到其实FP16的右半部分其实没有用到,我们可以把梯度乘以一个较大的值,从而让整个梯度分布向右移动,从而能够落在FP16的表示范围内。一个非常简单的方法就是在梯度计算前对loss乘以一个很大的值,这样根据链式求导法则,计算到的梯度都会被放大,当我们真正更新梯度的时候需要再将梯度缩小回来原来的值,用FP32进行更新。
-
Accumulation into FP32
在FP16的模型中,一些算术运算比如矩阵乘法需要用FP32来累加乘积的结果,然后再转换为FP16,这样的效果会更好一些。Tensor cores已经提供这种支持,这块其实我们不用太关心。
从前面的介绍来看,我们的模型训练过程更新如下,就可以使用混合精度进行训练了:
- Make an FP16 copy of the weights
- Forward propagate using FP16 weights and activations
- Multiply the resulting loss by the scale factor S
- Backward propagate using FP16 weights, activations, and their gradients
- Multiply the weight gradients by 1/S
- Optionally process the weight gradients (gradient clipping, weight decay, etc.)
- Update the master copy of weights in FP32
如果想要了解更多技术细节,可以阅读参考文献1和2。
实践
这里我们介绍tensorflow如何实现混合精度训练,nvidia和tensorflow已经为我们集成了很多功能,因此实现起来其实非常简单,只是我们要注意里面的一些细节,不然容易采坑。
-
有支持Tensor Core的GPU
-
阅读Nvidia关于混合精度训练的文档
我们在实验时遇到的很多坑其实在文档中已经提到过,因此仔细阅读官方的文档很重要。
具体参考文献3和4。
-
使用nvidia提供的tensorflow docker
前往Nvidia GPU Cloud下载19.03之后的docker,这会省去你很多配置环境,安装依赖的时间。
-
如何手动修改?
-
在计算密集的地方(如卷积或者矩阵乘法等)修改成tf.float16的数据类型,尽可能让你的代码都是在tf.float16下运行,因为FP16和FP32之间的转换(cast)会带来额外的性能消耗,也会带来精度损失。
-
确保可训练的参数都是FP32的,只有在前向和后向传播的时候转换为FP16,可以通过在定义scope的时候加上
float32_variable_storage_getter这个方法来实现,具体参考BERT中的实现。 -
确保softmax计算的时候用的是FP32,不然你就会得到一堆NAN或者INF
-
我们还需要做loss-scaling,一般我们没法提前确定到底要设置多大的scale,比较好的方法是在训练的时候动态调整scale,tf-1.13版本以上都有contrib类帮我们做好了,具体来说就是LossScaleManager和LossScaleOptimizer两个类,参考如下代码:
loss_scale_manager= tf.contrib.mixed_precision.ExponentialUpdateLossScaleManager(init_loss_scale=2**32, incr_every_n_steps=1000, decr_every_n_nan_or_inf=2, decr_ratio=0.5) optimizer = tf.contrib.mixed_precision.LossScaleOptimizer(optimizer, loss_scale_manager)简单来说这里的动态调整是这样做的:先取一个较大的scale值,在训练的过程中,如果N步迭代中都没有发生溢出那么就增加scale的值,否则就跳过溢出那一步的更新将scale减少再尝试。
-
参考代码
Nvidia官方给出了bert的手动修改的自动混合精度代码,参考BERT,该项目中还有其他模型也可以参考。
-
注意
虽然看起来改起来比较简单,但是这中间修改FP16格式可能会遇到各种问题,比如loss为NAN、显存消耗没有降低、速度没有太大提升等。一开始不建议手动改,还是用自动混合精度测试,如果速度没有太大提升可以再进一步手动修改。
-
-
自动混合精度(AMP)
自动混合精度会帮你处理好类型转换、梯度更新和loss-scaling的问题,我们只需要用到前面提到的nvidia的docker,设置一个环境变量即可:
export TF_ENABLE_AUTO_MIXED_PRECISION=1但是我们还是要注意以下一些问题:
- 最好使用官方的优化器
- 在计算梯度和更新梯度的时候使用optimizer.compute_gradients和optimizer.apply_gradients方法,否则Loss-scaling不work。
- 如果你确实要使用自己的优化器,那么使用LossScaleOptimizer封装你的优化器,确保loss scaling能够work
- 在进行梯度裁剪的时候,确保只有所有梯度都是finite的时候才进行,否则梯度裁剪会出错。可以参考这里的代码Clip。
- AMP已经自动帮你做了优化,所以特别注意自己手改的地方会不会影响到AMP。
-
Optimizing for Tensor Cores
为了最大化利用tensor cores来加速你的代码,还有一些额外的限制条件。基本上就是你的数据的维度,模型的维度都必须是8的倍数,这样才能充分利用tensor cores。
- For matrix multiplication: On FP16 inputs, all three dimensions (M, N, K) must be multiples of 8.
- For convolution: On FP16 inputs, input and output channels must be multiples of 8.
- Choose mini-batch to be a multiple of 8
- Choose linear layer dimensions to be a multiple of 8
- Choose convolution layer channel counts to be a multiple of 8
- For classification problems, pad vocabulary to be a multiple of 8
- For sequence problems, pad the sequence length to be a multiple of 8
- 还有一些诸如提高运算强度等,参考文献3。
-
其他注意事项
- 如果遇到一些问题可以回到参考文献3、4中查看一下是否有相关描述
- 关于多GPU的情况,目前官方表示还需要使用Horovod来实现,这个我们后面会介绍
XLA加速
什么是XLA?XLA全称是Accelerated Linear Algebra(线性代数加速)。我们知道tensorflow定义了很多运算符,并且对这些运算/指令(OP)分别进行了优化,从而使得其能够方便的构建任意的数据流图。这样做提高了灵活性,但是却会可能导致性能不高,因为用户仍然可以用底层的op来定义一些复杂的运算,这就会带来额外的消耗,比如存储中间数据,OP之间的数据交换等。举个例子来说,TF中有softmax运算,但是用户仍然可以通过指数、加法、除法等运算来实现,使用这些运算还可能会导致kernel的多次加载,从而使得速度变慢。
XLA就是自动优化这些op的组合,通过分析图的结构,融合(fuse)多个op形成一个op,从而产生更加高效的机器代码。
XLA目前还是属于实验阶段,而且官方文档中说绝大多数用户可能体会不到XLA的加速效果,但是其实使用起来还是比较方便的(指JIT,AOT的话还是有点麻烦)。我们在实验中发现XLA可以加速,但是有时候却会导致内存消耗增加一些。
如何使用XLA
-
AOT
AOT(Ahead-of-time)是指在运行前先将代码编译成可执行的代码,从而减小binary的大小和运行时的消耗。
但是AOT官方给的例子挺麻烦的,我们没有深入研究,所以对AOT感兴趣的同学可以阅读参考文献7。
-
JIT
JIT也即just-in-time,JIT编译和运行部分tensorflow的图,将多个op(内核)融合为少数的编译的内核,从而实现加速。
最简单的JIT使用方法是在session中通过config来开启,如下所示:
# Config to turn on JIT compilation config = tf.ConfigProto() config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_1 sess = tf.Session(config=config) -
注意
使用XLA并不一定能够得到加速和减少内存的效果,需要在实际中测试确定是否需要使用XLA。
分布式训练
正如前面介绍说到的,我们的模型可能会很大,或者数据量会很大。仅仅用一块GPU卡可能连模型都放不下,或者batch size只能设置的很小,但是我们知道有些情况下大的batch size往往会提供更好的效果。因此我们就需要用到分布式训练的技巧,这里的分布式训练包括了单机多卡和多机多卡的情况。
分布式训练策略
策略可以分成两种类型:
-
模型并行
当模型较大的时候,没法部署在单卡上,就需要把模型部署到多块卡上(这些卡可以在不同设备),比如把多层的LSTM的层分配到不同的卡上,这个通过tensorflow的tf.device可以很容易做到。典型的例子就是google的gnmt论文中提到的训练方法,就是模型并行。
实际上模型并行并不高效,因为层之间可能有依赖关系,从而使得效率并没有提高。而且现在显存不断加大,单卡放下模型还是可以实现的。
-
数据并行
数据并行是最常见的策略。数据并行是在多块卡上布置相同的模型,每个模型读取不同的训练样本进行训练,然后再收集梯度来更新参数。
数据并行也有两种类别:
-
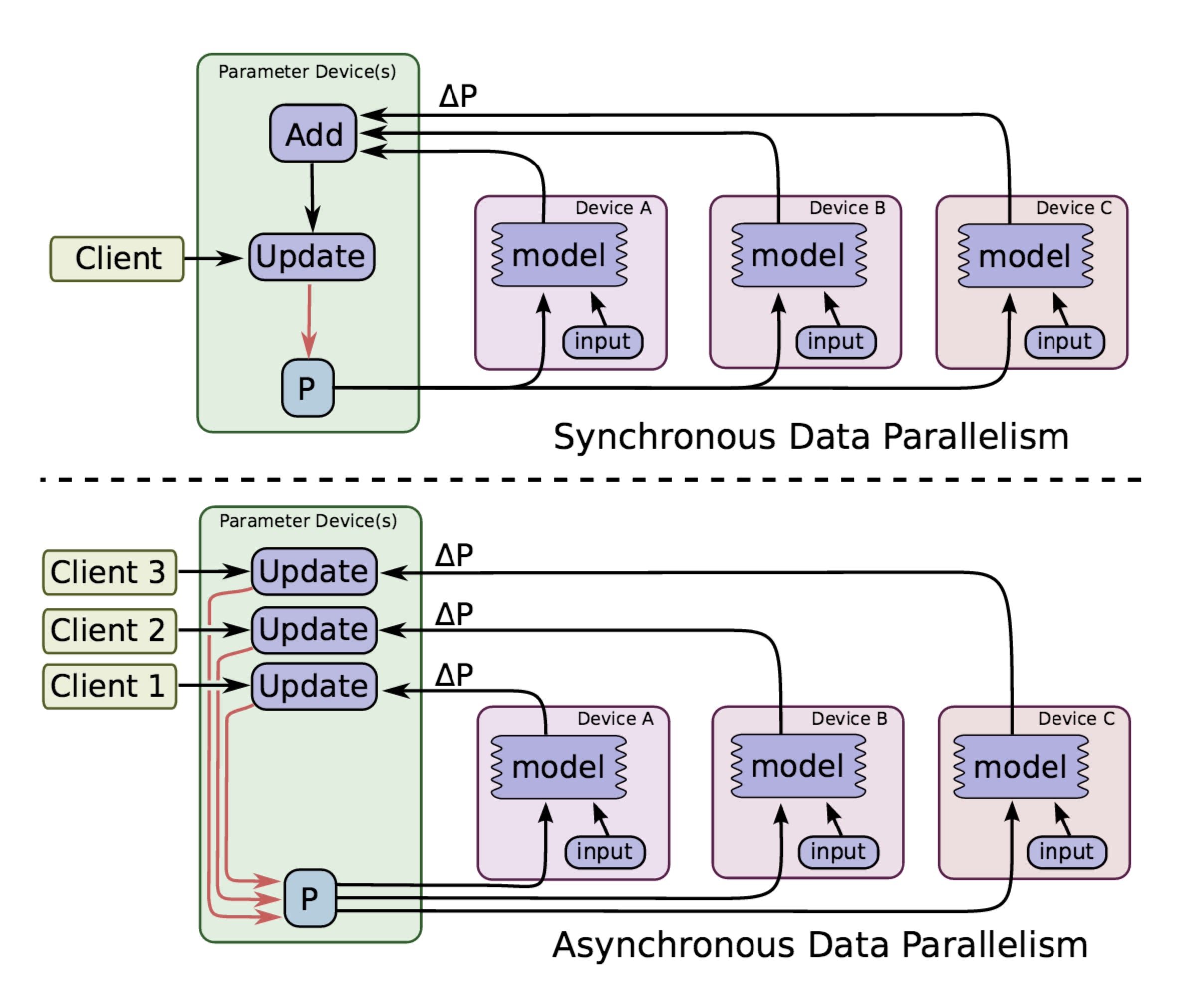
同步(syncronous)
所有模型的参数一样,等所有设备上的训练完成后再收集全部梯度取平均后进行更新,然后再用更新后的参数进行下一次迭代。
这种方法要求各个设备性能要一致,设备之间通信性能也要一致,不然就会出现其他设备等待最慢设备的现象,导致训练速度降低。
-
异步(asynchronous )
异步训练不需要等待其他设备完成训练就直接去更新参数,从而训练速度会比同步的快很多。但是异步训练会出现梯度失效的问题,比如某个设备训练完后发现参数已经被其他设备更新过了,那么自己根据较老的参数计算出来的梯度就过期了,直接用来进行更新就可能陷入局部次优解。这篇文章提到的例子可以有更直观的感受。
同步和异步的区别可以从下图看出:
-
数据并行策略的系统架构
这里我们主要关注数据并行的策略,在策略下我们怎么实现数据并行呢?
Parameter Server Architecture
在早前的tensorflow版本中的分布式训练中使用的就是PS架构。在PS架构中,我们会有参数服务器(parameter server)用来存放模型的参数,有worker来进行实际的模型训练。worker处理训练数据,计算梯度再发送回参数服务器,参数服务器将梯度平均后更新参数,再发送回各个worker。我们可以只设置一个PS也可以有多个PS(每个PS只处理一部分梯度),如下图所示:
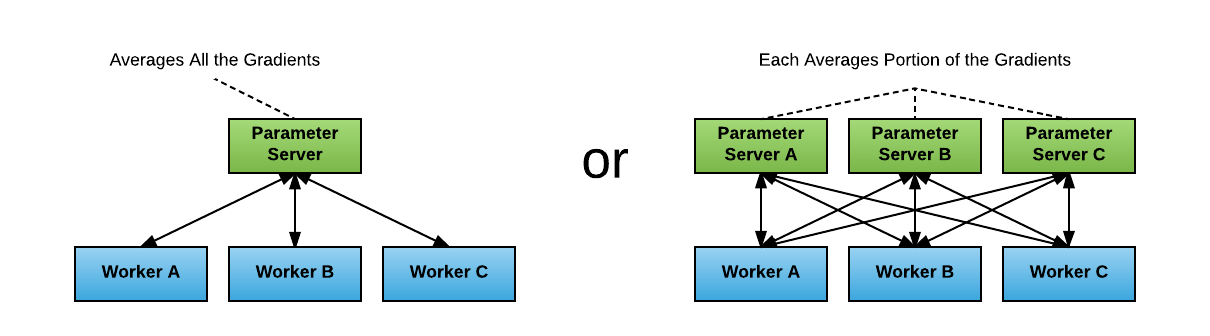
这种方法虽然直观,但是问题是如果只有1个PS,那么它和所有worker之间的梯度和参数传递会消耗很大的带宽,成为瓶颈,尤其是我们现在模型的参数动不动就上亿。如果有多个PS,那么通信模式变成all-to-all,网络间的连接数会大大增加,训练速度受到网络性能的影响。
Ring-AllReduce
如果你有很多GPU来跑模型训练,你挑选了其中一块GPU来作为参数更新的Master机器,那么它就要接收所有其他GPU的数据更新后再广播出去,这是一种all-reduce的操作。这里的问题就是参数量大的情况下,训练速度受到网络带宽的限制。
为了解决这个问题提出了Ring-AllReduce的方法。这时候每个GPU都是worker也是PS,它们构成一个逻辑上的环结构,每个GPU都有左邻和右邻,如下图所示。
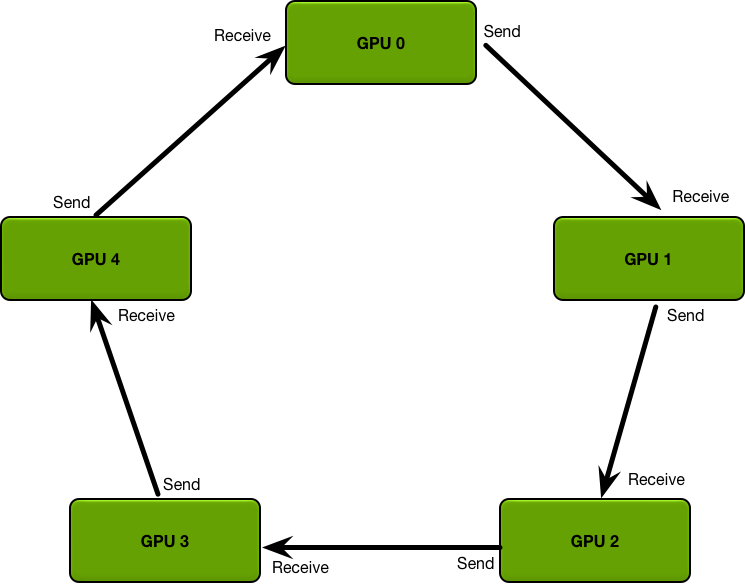
假设有个N个GPU,每个GPU计算完梯度后将梯度分成N个部分,向下一个GPU传递其中一部分梯度,并且从上一个GPU接受一部分梯度,这两部分梯度是不一样的。每个GPU处理自己和从上一个GPU发送过来的梯度。最后直到每个GPU都含有最终梯度的部分数据;最后GPU之间再将梯度进行分发从而完成更新。这个具体包括Scatter-Reduce和Allgather两个步骤,可以参考文献9了解更详细的过程。
相比PS架构,Ring-allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。
实践
目前tensorflow如果你使用estimator的话,使用分布式还是比较简单的,它内置已经帮我们做了很多操作,而且还提供了很多分布式的策略供选择,但是就是要求你要按照它的形式来构建训练的pipeline,比如input_fn和model_fn等。但是还是建议大家还是用estimator来构建模型的训练,毕竟是官方推荐的,支持也更多。具体可以参考文献13和14。
这里我们介绍另外一个非常简单的工具-Horovod,他是uber开源的分布式框架,利用MPI实现了Ring-allreduce的操作,使用起来也比较简单。
Horovod
简单介绍如何使用Horovod和注意的事项。
-
使用Nvidia的docker
已经安装了Horovod,省去配置环境的问题(比如MPI的安装)。
使用NCCL 2可以显著的提高性能,目前我还没有研究nvidia的dokcer是否安装了NCCL 2
-
使用步骤
tensorflow的使用步骤可以参考官方的代码文档,下面是简单的代码示例:
import tensorflow as tf import horovod.tensorflow as hvd # Initialize Horovod hvd.init() # Pin GPU to be used to process local rank (one GPU per process) config = tf.ConfigProto() config.gpu_options.visible_device_list = str(hvd.local_rank()) # Build model... loss = ... opt = tf.train.AdagradOptimizer(0.01 * hvd.size()) # Add Horovod Distributed Optimizer opt = hvd.DistributedOptimizer(opt) # Add hook to broadcast variables from rank 0 to all other processes during # initialization. hooks = [hvd.BroadcastGlobalVariablesHook(0)] # Make training operation train_op = opt.minimize(loss) # Save checkpoints only on worker 0 to prevent other workers from corrupting them. checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None # The MonitoredTrainingSession takes care of session initialization, # restoring from a checkpoint, saving to a checkpoint, and closing when done # or an error occurs. with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir, config=config, hooks=hooks) as mon_sess: while not mon_sess.should_stop(): # Perform synchronous training. mon_sess.run(train_op)这里关键的几点:
- config的gpu_option需要改成hvd来控制
- 注意到学习率这里乘了hvd.size(),这是根据facebook的论文Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour提到的trick。但是我觉得除非你的batch size是特别大的,否则可以不需要这个操作
- 需要用DistributedOptimizer来封装optimizer,从而保证梯度的正确计算和传递
- BroadcastGlobalVariablesHook的作用是保证每个模型都使用相同的初始化参数来训练,如果不想要hook还可以在初始化全局变量后使用hvd.broadcast_global_variables来替代
- checkpoint_dir这里是为了防止不同进程将数据写入同一个目录下
-
数据问题
horovod并没有做数据split的事情,所以batch size需要根据gpu的内存情况设置,假设你有4个gpu,设置的batch size是32,那么每一步训练的数据大小其实是4*32=128。
我们需要保证每个GPU处理的数据都是不同的,不然分布式训练就没有意义了。要做到这点,有下面几种方法:
- 加入sampling的机制,从而每个GPU读取的数据不同
- 如果使用的是tf.data模块,还可以用shard机制,这个适合数据量太大,你的输入有多个文件的情况
梯度累积
我们在学算法的时候常见的两个技巧是:时间换空间和空间换时间。假设我们只有一个GPU,我们的模型一次只能输入batch size为8的数据,那么我们怎么样实现batch size为32的更新呢?那就需要时间换空间了,即我们训练32/8=4步才去更新模型,也就是所谓的梯度累积。
这个在tensorflow中实现起来也比较简单,首先构建额外的参数来记录梯度值,在训练的时候将每一步计算得到的梯度值加到里面,当达到预先设置的累积次数的时候,再一次性的进行梯度更新。这里要注意的是,累加的梯度要除以累加的次数,不然就相当于放大了梯度【参考文献15】。
具体的代码可以参考OpenNMT-tf的实现。
我们可以把梯度累积和分布式训练(Horovod)结合起来使用,但是在Horovod的DistributedOptimizer类中allreduce操作是在compute_gradients中做的,那么带来的问题就是每一步计算梯度都会带来allreduce操作。其实我们可以只在梯度累积结束后再做allreduce来同步梯度,所以我们需要修改DistributedOptimizer类的方法,在apply_gradients之前allreduce即可。
前面说的情况都是模型可以至少在GPU上运行batch size为1的数据,那么如果你的GPU连batch size为1都跑不了怎么办?这个时候建议换个更好的GPU吧。如果连GPU不能换,怎么办?还真有办法,也是我们前面说的时间换空间的方法。
Gradient-Checkpointing
我们在训练深度学习模型的时候,需要先做前向传播,然后将中间得到的激活值存储在内存中,然后反向传播的时候再根据loss和激活值计算梯度。也就是说内存消耗其实跟模型的层数线性相关。那么怎么减少这个内存消耗呢?最简单的想法就是我不存这些中间信息,计算梯度的时候,到了某一层我重新计算它的激活值,这个方法虽然可以让内存消耗是个常量,但是运行时间会是$O(n^2)$,这是没法接受的。
那么就有一个折中的办法,我不存全部的中间数据,只存部分,如下图所示。那么我们在计算梯度的时候不需要从头计算了,只需要从最近的checkpoint点计算就好。

使用该方法可以在时间增加20%的情况下,训练10倍大小的模型。感兴趣的可以参阅文献16。
实验
我们用了4台2080TI的机器,使用了Nvidia 19.06-py3的docker进行实验。单台GPU的batch size设为8,seq len为368。在不加AMP的情况下,没法在单台GPU上运行模型,在加了AMP和XLA后,显存占用为10G。使用了Horovod作为分布式的工具,测试发现每一步的时间大概在0.8s左右,训练了4天左右,ppl收敛到11,没有再继续训练下去。
后面加入了梯度累积,修改了原来的Horovod的Optimizer,在apply_gradients之前才做梯度的聚合,梯度累积步数设置为10。实验发现使用梯度累积后单步运行时间降到了0.4s,这说明原来的梯度聚合是在每一步做的,频繁的reduce操作导致模型花费了很多时间在等待上。但是使用梯度累积后收敛速度变慢,这是因为更新次数减少了,这也是时间换空间带来的问题,我们期望使用梯度累积的模型在最终效果上会好一些。
结语
上面提到的各种方法其实我们都是可以组合使用的,比如混合精度+Horovod+梯度累积一起使用,可以让你在有限资源的机器上,尽可能快的训练大的模型,但是尤其就是要注意梯度更新的问题。
还可以看到,混合精度和Ring-AllReduce都有百度的身影,不得不表扬一下百度为模型训练加速这块做的贡献,至少说明百度技术还是很厉害的,就是要用在对的地方。
参考文献
- Mixed Precision Training
- Mixed-Precision Training of Deep Neural Networks
- Training With Mixed Precision
- Performance
- BERT code
- XLA - TensorFlow, compiled
- Using AOT compilation
- Using JIT Compilation
- Bringing HPC Techniques to Deep Learning
- 分布式TensorFlow入门教程
- Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow
- Horovod
- Distributed Training in TensorFlow
- Multi-worker Training with Estimator
- Accumulated Gradient in Tensorflow
- Saving memory using gradient-checkpointing